پروتئین چیست؟
مولکولهای پروتئین، مانند DNA و RNA، زنجیرههای بلند و بدون شاخهای از پلیمرها هستند که از کنار هم قرار گرفتن واحدهای سازندهای بهنام آمینو اسیدها ساخته میشوند. این آمینو اسیدها از یک مجموعه استاندارد تشکیل شدهاند که در تمام موجودات زنده یکسان است. همانطور که در زبان نوشتاری، پیام با استفاده از الفبای خاصی منتقل میشود، پروتئینها نیز اطلاعات خود را از طریق توالی خطی آمینو اسیدها ذخیره و بیان میکنند.
در هر سلول، انواع مختلفی از پروتئینها وجود دارد و اگر آب را در نظر نگیریم، بیشتر جرم سلول از همین پروتئینها تشکیل شده است.
واحدهای سازنده پروتئین، یعنی آمینو اسیدها، برخلاف نوکلئوتیدهای DNA و RNA، متنوعترند—بهجای چهار نوع، ۲۰ نوع مختلف دارند. هر آمینو اسید دارای یک ساختار مرکزی یکسان است که امکان اتصال استاندارد به سایر آمینو اسیدها را فراهم میکند. تفاوت هر آمینو اسید با دیگری در گروه جانبی آن است که ویژگیهای شیمیایی خاصی به آن میبخشد.
هر مولکول پروتئین، یک پلیپپتید است که از بههم پیوستن آمینو اسیدها به ترتیب مشخصی تشکیل میشود. این توالی خاص در طول میلیاردها سال تکامل به شکلی انتخاب شده تا عملکردی مفید برای سلول داشته باشد. پروتئینها با تا شدن در ساختاری دقیق و سهبعدی، که سطح آن شامل نواحی واکنشپذیر است، میتوانند بهطور اختصاصی به مولکولهای دیگر متصل شوند.
برخی از پروتئینها بهعنوان آنزیمها عمل میکنند—مولکولهایی که با سرعت بخشیدن به واکنشهای شیمیایی، باعث ساخته شدن یا شکستن پیوندهای کووالانسی میشوند. به این ترتیب، پروتئینها بخش عمدهای از واکنشها و فرآیندهای شیمیایی درون سلول را کنترل و هدایت میکنند.
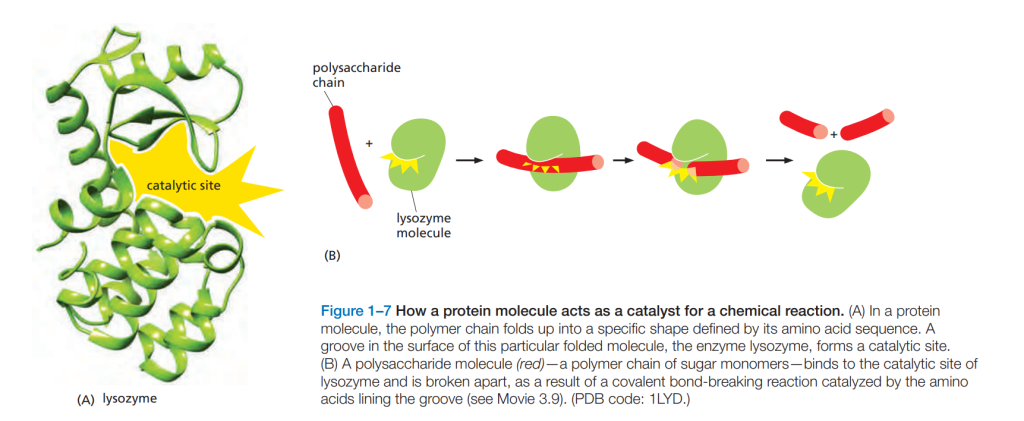
پروتئینها تنها به کاتالیز واکنشهای شیمیایی محدود نمیشوند؛ آنها در بسیاری از عملکردهای حیاتی دیگر نیز نقش دارند—از جمله حفظ ساختارهای سلولی، ایجاد حرکت، دریافت و پاسخ به سیگنالها و موارد دیگر. هر مولکول پروتئین، بر اساس توالی خاصی از آمینو اسیدهایی که توسط ژنها تعیین شدهاند، عملکرد مشخصی را در سلول ایفا میکند.
در واقع، پروتئینها اصلیترین مولکولهایی هستند که اطلاعات ژنتیکی سلول را به عمل تبدیل میکنند.
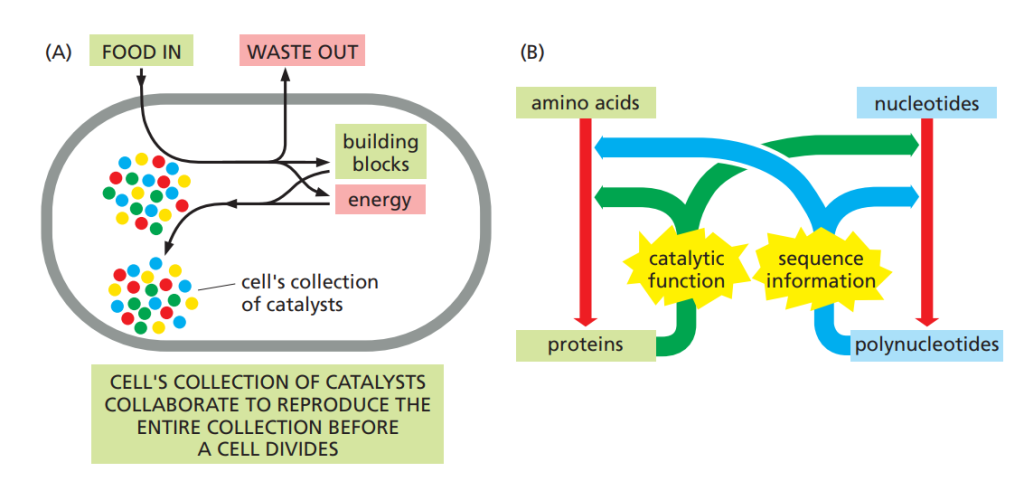
بهعبارت دیگر، پلینوکلئوتیدها (مانند DNA و RNA) توالی آمینو اسیدهای پروتئینها را مشخص میکنند، و پروتئینها نیز بسیاری از واکنشهای شیمیایی—including سنتز DNA جدید—را کاتالیز میکنند. از این دیدگاه بنیادی، میتوان یک سلول زنده را مجموعهای خودتکثیرشونده از کاتالیزورها دانست که مواد غذایی را دریافت میکند، آنها را پردازش میکند تا انرژی و اجزای مورد نیاز برای ساخت کاتالیزورهای بیشتر را تولید کند، و مواد زائد را دفع مینماید.
این چرخه بهوسیله یک حلقه بازخوردی میان پروتئینها و پلینوکلئوتیدها برقرار میشود—حلقهای که پایه رفتار خودکاتالیز و خودتولیدی موجودات زنده را شکل میدهد.
در خصوص اپی ژنتیک بیشتر بدانید
در دهه ۱۹۵۰، زمانی که ساختار دو رشتهای DNA بهعنوان پایه وراثت کشف شد، این پرسش اساسی که چگونه اطلاعات موجود در DNA منجر به ساخت پروتئینها میشود، هنوز بهطور کامل ناشناخته بود. اما در سالهای بعد، دانشمندان موفق شدند سازوکارهای پیچیده و زیبای این فرایند را کشف کنند.
فرآیند ترجمه اطلاعات ژنتیکی از الفبای چهارحرفی پلینوکلئوتیدها (A، U، G، C) به الفبای بیستحرفی پروتئینها (آمینو اسیدها) فرآیندی بسیار دقیق و منظم است. قوانین این ترجمه از یکسو منطقی و منظم بهنظر میرسند، اما از سوی دیگر، برخی ویژگیهای آن، کاملاً تصادفی و دلخواه هستند. با این حال، این ویژگیهای به ظاهر «دلبخواهی» تقریباً در تمام موجودات زنده یکساناند. دانشمندان بر این باورند که این ویژگیها بازتابی از تصادفهای منجمدشده در تاریخ اولیهی حیات هستند—یعنی ویژگیهایی که بهصورت اتفاقی در نخستین جانداران پدید آمدند و از آن زمان از طریق وراثت حفظ شدهاند، بهطوریکه دیگر امکان تغییر آنها وجود ندارد بدون آنکه پیامدهای فاجعهباری برای سلول به همراه داشته باشد.
اطلاعات موجود در توالی یک مولکول RNA پیامرسان (mRNA) بهصورت گروههای سهتایی از نوکلئوتیدها خوانده میشود. هر سهتایی، که به آن کدون (codon) گفته میشود، یک آمینواسید خاص را در پروتئین مشخص میکند. از آنجا که میتوان از چهار نوکلئوتید، تعداد ۴³ یا ۶۴ کدون متفاوت ساخت، اما تنها ۲۰ آمینواسید طبیعی وجود دارد، ناگزیر چندین کدون مختلف میتوانند به یک آمینواسید خاص اشاره کنند.
کد ژنتیکی توسط گروهی از RNAهای کوچک بهنام tRNA (RNA ناقل) خوانده میشود. هر نوع tRNA در یک سمت خود، به یک آمینواسید خاص متصل میشود و در سمت دیگر خود، یک توالی سهتایی خاص بهنام آنتیکدون دارد. این آنتیکدون از طریق جفتشدن بازها، کدون مکمل خود را در mRNA شناسایی میکند. این tRNAها نقش کلیدی در رمزگشایی توالیهای A، U، G، C در mRNA و تبدیل آنها به توالی آمینواسیدی در پروتئین دارند.
تمام این فرایند پیچیده و دقیق، بر روی ریبوزوم انجام میشود—ماشینی بزرگ و چندمولکولی که از پروتئین و RNA ریبوزومی (rRNA) ساخته شده است.
تمام این فرایندها در فصل ششم بهتفصیل توضیح داده میشوند.
هر پروتئین توسط یک ژن خاص کُدگذاری میشود
مولکولهای DNA معمولاً بسیار بزرگ هستند و اطلاعات مربوط به هزاران پروتئین را در خود جای میدهند. توالیهای خاصی در DNA نقش علامتگذاری و نشانهگذاری را ایفا میکنند؛ آنها مشخص میکنند که اطلاعات مربوط به هر پروتئین از کجا آغاز شده و کجا پایان مییابد.
بخشهای جداگانهای از این توالی طولانی DNA بهصورت مستقل رونوشتبرداری میشوند و هر رونوشت mRNA، اطلاعات ساخت یک پروتئین متفاوت را در بر دارد. هر یک از این بخشهای DNA را یک ژن مینامند.
با این حال، موضوع پیچیدهتر از این است: در بسیاری از موارد، RNA حاصل از یک قطعهی مشخص از DNA، میتواند به روشهای مختلف پردازش شود و در نتیجه، چند نسخهی متفاوت از یک پروتئین (ایزوفرمها) تولید کند—این پدیده بهویژه در سلولهای پیچیدهتر مانند سلولهای گیاهی و جانوری رایج است.
علاوه بر این، برخی از بخشهای DNA—اگرچه تعدادشان کمتر است—به RNAهایی تبدیل میشوند که به پروتئین ترجمه نمیشوند، اما نقشهایی آنزیمی، تنظیمی یا ساختاری دارند. این نوع بخشهای DNA نیز جزو ژنها محسوب میشوند.
در نتیجه، ژِن به بخشی از توالی DNA گفته میشود که میتواند به یکی از موارد زیر منجر شود:
یک پروتئین خاص
مجموعهای از نسخههای جایگزین یک پروتئین (بهواسطهی پردازشهای متفاوت RNA)
یک RNA غیررمزکننده با عملکرد آنزیمی، تنظیمی یا ساختاری
در تمامی سلولها، بیان ژنها (gene expression) بهصورت تنظیمشده انجام میشود. یعنی سلول بهجای اینکه همهی پروتئینهای ممکن را همزمان و با حداکثر ظرفیت بسازد، میزان رونویسی و ترجمهی هر ژن را بهصورت مستقل، بر اساس نیاز تنظیم میکند.
بخشهایی از DNA که کد پروتئین نیستند، اما عملکرد تنظیمی دارند، در میان ژنها پراکندهاند. این نواحی تنظیمی به پروتئینهای خاصی متصل میشوند که نرخ رونویسی را در محل مورد نظر کنترل میکنند. مقدار و نحوهی سازماندهی DNA تنظیمی در بین انواع مختلف جانداران تفاوت زیادی دارد، اما راهبرد کلی آن جهانی و مشترک است.
به این ترتیب، ژنوم سلول—یعنی کل اطلاعات ژنتیکی موجود در توالی DNA آن—نهتنها نوع پروتئینهای سلول را تعیین میکند، بلکه زمان و مکان تولید آنها را نیز مشخص میسازد.
حیات به انرژی آزاد نیاز دارد
یک سلول زنده، یک سامانهی شیمیایی پویا است که در وضعیت تعادل شیمیایی قرار ندارد و بسیار دور از آن فعالیت میکند. برای اینکه سلول رشد کند یا سلول جدیدی مشابه خودش بسازد، باید انرژی آزاد را از محیط بگیرد—علاوه بر مواد خام مورد نیاز—تا واکنشهای ترکیبی (سنتزی) ضروری را به پیش ببرد.
این مصرف انرژی آزاد، اساس حیات است.
وقتی این فرآیند متوقف شود، سلول بهتدریج به سمت تعادل شیمیایی پیش میرود و بهزودی میمیرد.
اطلاعات ژنتیکی نیز برای ادامهی حیات ضروری است و انتقال و حفظ این اطلاعات نیازمند انرژی آزاد است. بهعنوان مثال، حتی برای مشخص کردن یک بیت اطلاعات—یعنی یک انتخاب ساده بین دو گزینهی برابر (بله/خیر یا صفر/یک)—مقدار مشخصی انرژی آزاد مصرف میشود که قابل محاسبه است.
این رابطهی کمی، از منطق عمیقی برخوردار است و به تعریف دقیق واژهی “انرژی آزاد” بستگی دارد (که در فصل ۲ توضیح داده خواهد شد).
با این حال، اصل ماجرا را میتوان بهسادگی بهصورت شهودی درک کرد:
تصور کن که مولکولهای درون یک سلول مانند جمعیتی از اجسام پرانرژی هستند که بهصورت تصادفی و با خشونت حرکت میکنند و در اثر برخورد با یکدیگر دائماً منحرف میشوند.
در سلول، فرآیندهای شیمیایی مربوط به انتقال اطلاعات بسیار پیچیدهتر هستند،
اما اصل پایهای همان است: ایجاد نظم، نیازمند صرف انرژی آزاد است.
بنابراین، برای اینکه سلول بتواند اطلاعات ژنتیکی خود را با دقت بازتولید کند و تمام مولکولهای پیچیدهی خود را بهدرستی بسازد، نیاز به انرژی آزاد دارد.
این انرژی باید بهنحوی از محیط اطراف وارد شود.
همانطور که در فصل ۲ خواهیم دید:
سلولهای جانوری انرژی آزاد خود را از پیوندهای شیمیایی موجود در مولکولهای غذایی بهدست میآورند،
در حالی که گیاهان این انرژی را از نور خورشید دریافت میکنند.
پیوندهایی که این مولکولها را در جای خود نگه میدارند و آنها را به هم متصل میکنند، باید آنقدر محکم باشند که در برابر آشفتگی ناشی از انرژی حرارتی مقاومت کنند.
این فرآیند با مصرف انرژی آزاد به جلو رانده میشود—انرژیای که لازم است تا این پیوندها درست و پایدار ایجاد شوند.
در سادهترین حالت، میتوان این مولکولها را مانند تلههای فنردار در نظر گرفت که آمادهاند تا وقتی با شریک مناسب خود روبهرو شوند، به حالت پایدارتر و کمانرژیتر بچسبند. وقتی این اتفاق میافتد، انرژی ذخیرهشدهی آنها—یعنی انرژی آزادشان—آزاد شده و بهصورت گرما از بین میرود.
همهی سلولها مانند کارخانههای بیوشیمیایی عمل میکنند و با بلوکهای ساختمانی مولکولی مشترکی سروکار دارند
از آنجا که همهی سلولها DNA، RNA و پروتئین میسازند، باید مجموعهای مشابه از مولکولهای کوچک را در اختیار داشته و با آنها کار کنند—از جمله قندهای ساده، نوکلئوتیدها، و اسیدهای آمینه—و همچنین سایر موادی که بهطور جهانی مورد نیاز هستند.
برای مثال، همهی سلولها به نوکلئوتید فسفریلهشدهی ATP (آدنوزین تریفسفات) نیاز دارند؛ نهتنها بهعنوان یکی از اجزای سازندهی DNA و RNA، بلکه بهعنوان حامل انرژی آزاد که برای پیش بردن تعداد زیادی از واکنشهای شیمیایی درون سلول ضروری است.
گرچه تمام سلولها از نظر کلی شبیه کارخانههای بیوشیمیایی هستند،
اما جزئیات واکنشها و مسیرهای مربوط به مولکولهای کوچک در آنها میتواند متفاوت باشد.
برای مثال:
برخی از جانداران مانند گیاهان، تنها به سادهترین مواد مغذی نیاز دارند و با بهرهگیری از انرژی نور خورشید، میتوانند همهی مولکولهای آلی کوچک مورد نیاز خود را بسازند.
در مقابل، جاندارانی مانند جانوران، از موجودات زندهی دیگر تغذیه میکنند و باید بسیاری از مولکولهای آلی مورد نیاز خود را بهشکل آماده از طریق تغذیه دریافت کنند.
همهی سلولها توسط غشای پلاسمایی احاطه شدهاند که مواد مغذی و مواد زائد باید از آن عبور کنند
یکی دیگر از ویژگیهای جهانی سلولها این است که هر سلول توسط یک غشا ــ که به آن غشای پلاسمایی گفته میشود ــ احاطه شده است.
این غشا مانند یک سد انتخابی عمل میکند؛ به سلول اجازه میدهد که مواد مغذی را از محیط اطراف دریافت و درون خود متمرکز کند،
محصولات ساختهشدهی خود را نگه دارد، و در عین حال، مواد زائد را دفع کند.
اگر سلول فاقد غشای پلاسمایی باشد، نمیتواند یک سیستم شیمیایی منسجم و هماهنگ باقی بماند.
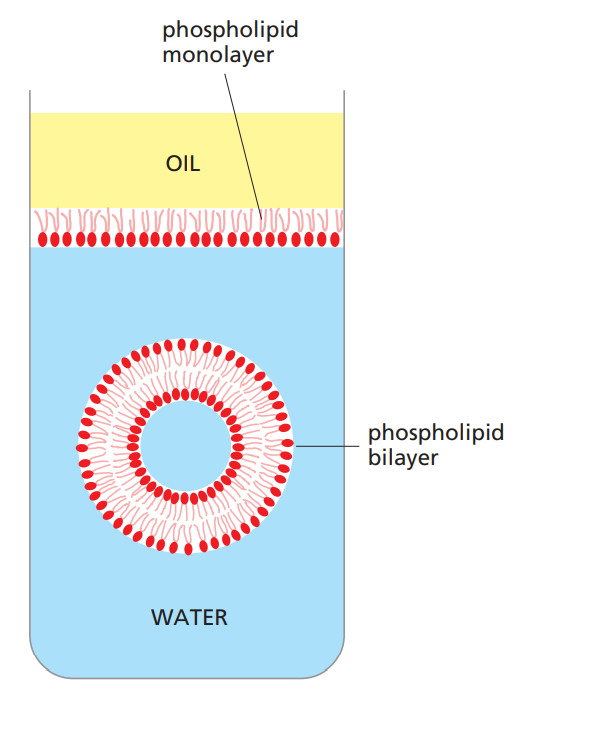
مولکولهایی که ساختار غشا را تشکیل میدهند، یک ویژگی فیزیکوشیمیایی ساده دارند:
آنها آمفیفیلیک هستند؛ یعنی دارای یک بخش آبگریز (نامحلول در آب) و یک بخش آبدوست (محلول در آب) هستند.
وقتی این مولکولها در محیط آبی قرار میگیرند، بهطور خودبهخودی تجمع میکنند:
بخشهای آبگریزشان را از تماس با آب دور نگه میدارند و آنها را به سمت یکدیگر سوق میدهند،
در حالی که بخشهای آبدوست را در معرض تماس با آب نگه میدارند.
مولکولهای آمفیفیلیک مناسب، مانند فسفولیپیدها که بخش عمدهی غشای پلاسمایی را تشکیل میدهند،
در آب بهصورت خودبهخودی دو لایهای تشکیل میدهند که ساختارهای وزیکول بسته را ایجاد میکند.
این پدیده را میتوان حتی در لوله آزمایش هم مشاهده کرد؛
کافی است فسفولیپیدها را با آب مخلوط کنید تا، در شرایط مناسب، وزیکولهایی تشکیل شوند که محتوای درونشان از محیط بیرون جدا شده است.
اگرچه جزئیات شیمیایی غشا در موجودات مختلف متفاوت است، اما در همهی آنها،
زنجیرههای آبگریز فسفولیپیدها از پلیمرهای هیدروکربنی (مانند –CH₂–CH₂–CH₂–) ساخته شدهاند.
تشکیل خودبهخودی ساختار دولایهی وزیکولی، تنها یکی از نمونههای اصل مهمتری است:
سلولها مولکولهایی تولید میکنند که ویژگیهای شیمیاییشان باعث میشود بهصورت خودبهخودی به ساختارهایی تبدیل شوند که سلول به آنها نیاز دارد.
مرز سلول نمیتواند کاملاً نفوذناپذیر باشد.
برای اینکه سلول بتواند رشد کرده و تکثیر یابد، باید توانایی وارد کردن مواد خام و خارج کردن مواد زائد از طریق غشای پلاسمایی را داشته باشد.
به همین دلیل، همهی سلولها دارای پروتئینهای تخصصی در غشای خود هستند که انتقال مولکولهای خاص از یک سوی غشا به سوی دیگر را بر عهده دارند.
برخی از این پروتئینهای انتقالی، مشابه آنزیمهایی که واکنشهای شیمیایی درون سلول را انجام میدهند،
چنان در طول تکامل حفظ شدهاند که شباهتهای خانوادگی آنها حتی در موجودات بسیار دور از نظر تکاملی نیز قابل شناسایی است.
در نهایت:
پروتئینهای انتقالی در غشا تعیین میکنند که چه مولکولهایی میتوانند وارد سلول شوند.
پروتئینهای کاتالیزوری درون سلول مشخص میکنند که این مولکولها وارد چه واکنشهایی میشوند.
در نتیجه، اطلاعات ژنتیکی ثبتشده در DNA با تعیین نوع پروتئینهایی که سلول باید بسازد،
نهتنها شیمی سلول، بلکه شکل و رفتار آن را نیز تعیین میکند؛
چرا که این موارد نیز عمدتاً توسط پروتئینهای سلول ساخته و کنترل میشوند.
یک سلول زنده میتواند با کمتر از ۵۰۰ ژن وجود داشته باشد
اصول پایهی انتقال اطلاعات زیستی نسبتاً سادهاند،
اما سلولهای زندهی واقعی تا چه اندازه پیچیده هستند؟
بهویژه، حداقل نیازهای یک سلول زنده چیست؟
برای پاسخ تقریبی به این پرسش، میتوان به یکی از موجوداتی اشاره کرد که کوچکترین ژنوم شناختهشده را دارد:
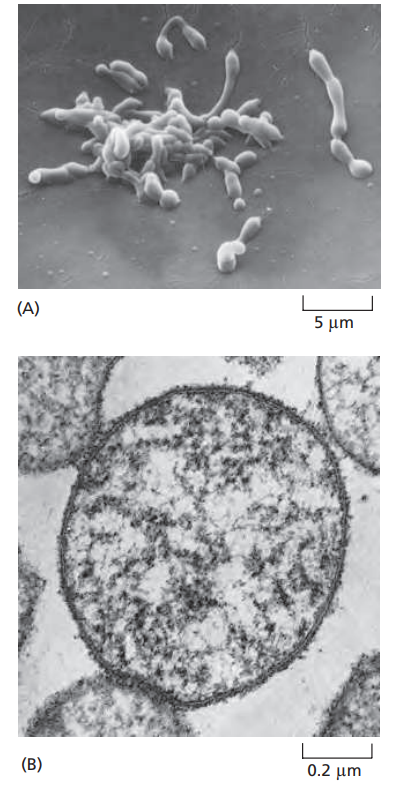
باکتری Mycoplasma genitalium (شکل ۱–۱۰).
این ارگانیسم بهصورت انگل در پستانداران زندگی میکند و محیط زندگیاش،
بسیاری از مولکولهای کوچک مورد نیازش را بهصورت آماده فراهم میکند.
با این حال، این باکتری هنوز باید تمام مولکولهای بزرگ مورد نیاز برای فرایندهای اساسی وراثت، یعنی
DNA، RNAها و پروتئینها را خودش بسازد.
مطالعات نشان دادند که این ICR دارای ۴ جایگاه اتصال برای فاکتور CTCF است. زمانی که این جایگاهها متیله یا حذف میشوند، اتصال CTCF مختل شده و عملکرد بلوکهکننده تقویتکننده را از دست میدهد. به بیان دیگر، متیلاسیون این ناحیه تعیین میکند که تقویتکننده به کدام پروموتر (Igf2 یا H19) متصل شود. این یافتهها نشان دادند که متیلاسیون در خارج از پروموترها نیز میتواند نقش مهمی در تنظیم ساختار سهبعدی DNA و کنترل بیان ژن داشته باشد.
این باکتری حدود ۵۳۰ ژن دارد که تقریباً ۴۰۰ تای آنها ضروری هستند.
ژنوم آن شامل ۵۸۰٬۰۷۰ جفت نوکلئوتید است که معادل ۱۴۵٬۰۱۸ بایت اطلاعات میباشد—
تقریباً به اندازهی حجم متنی که برای نگارش یک فصل از این کتاب لازم است.
بنابراین، زیستشناسی سلولی شاید پیچیده باشد، اما غیرقابلفهم یا غیرقابلدستیابی نیست.
در مجموع، حداقل تعداد ژنهای لازم برای یک سلول قابلحیات در شرایط محیطی امروزی احتمالاً کمتر از ۳۰۰ ژن نیست؛
اگرچه تنها حدود ۶۰ ژن در میان تمام گونههای زنده مشترک هستند و هستهی اصلی ژنها را تشکیل میدهند.
به دنبال این یافته، پژوهشگران در گیاه Arabidopsis نیز نشان دادند که آنزیم KRYPTONITE، که مسئول متیلاسیون H3K9 است، برای متیلاسیون نوع خاصی از توالیها توسط آنزیم CMT3 ضروری است. آنها همچنین دریافتند که LHP1، همسان پروتئین HP1 در حیوانات، با CMT3 تعامل دارد. این یافتهها پل ارتباطی مهمی میان اصلاحات هیستونی و متیلاسیون DNA در حیوانات و گیاهان برقرار کردند.